Local LLMs
Run standard models securely on local hardware. Access via OpenWebUI for chat or integrate directly into VS Code with AI Toolkit for private, offline code development.
Launch App →Complete Local LLM Setup, Home Automation Integration, and Private RAG Solutions. Your data stays on your hardware.
Start Your SetupWe build high-performance local AI servers using Ollama and NVIDIA hardware. Run Llama 3, Mistral, and more without monthly fees.
Learn MoreIntegrate Voice AI with Home Assistant. Control your lights, security, and climate with a private voice assistant that actually listens.
Learn MoreChat with your personal documents (PDFs, Finance, Legal) securely. No data ever leaves your local network.
Learn MoreMentoring for FIRST Lego League, competitive robotics, and hands-on STEM workshops. Building the next generation of engineers.
Get InvolvedYour personal AI nutritionist. Log meals by text or photo, track macro-nutrients, and get instant health advice.
Launch AppExplore the innovative tools and games built by The AI Labs.
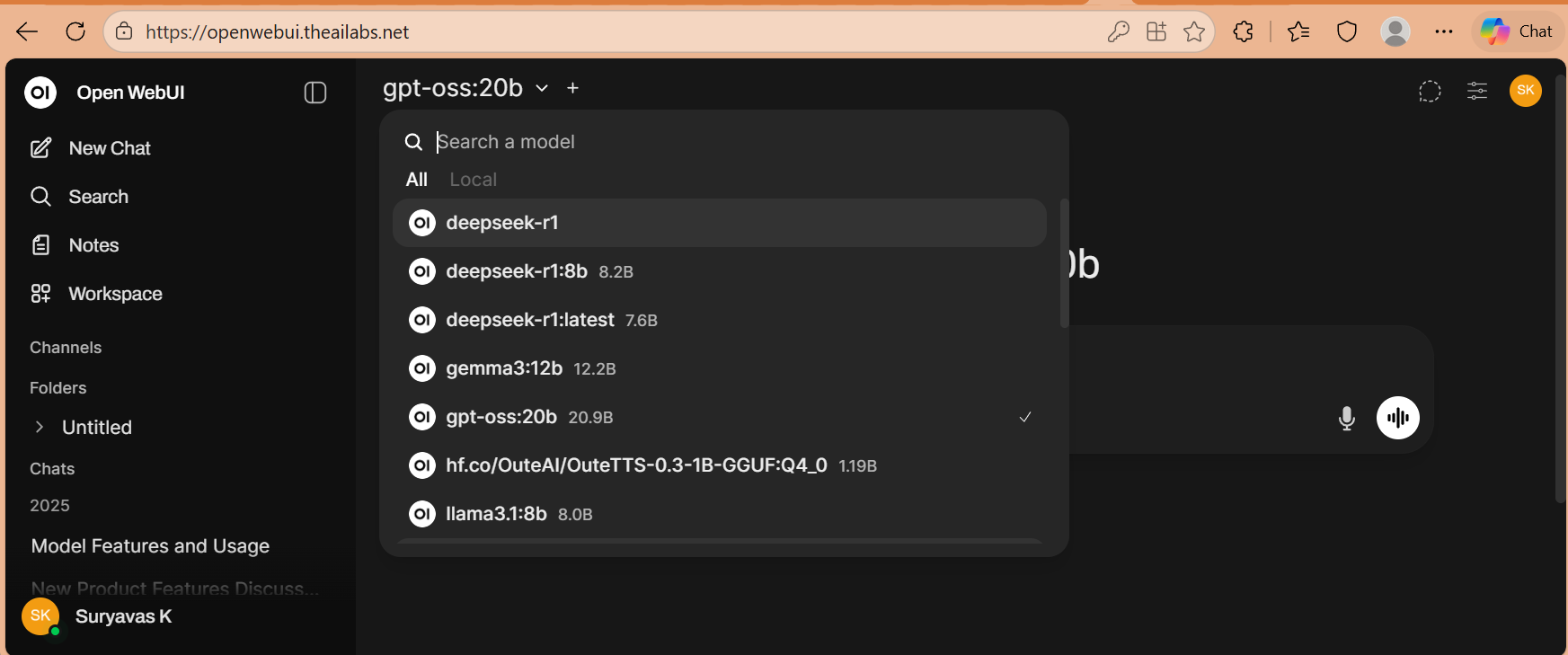
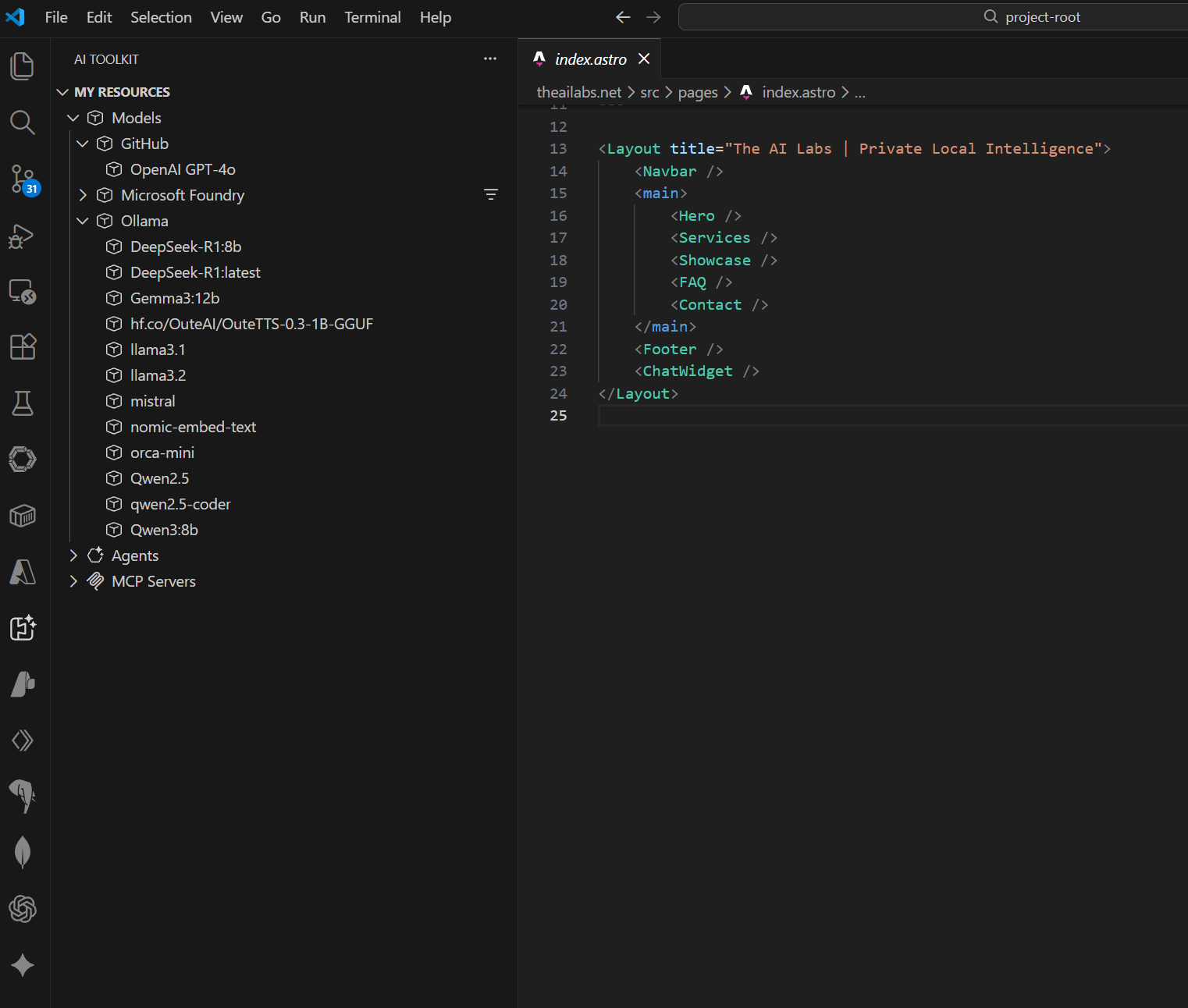
Run standard models securely on local hardware. Access via OpenWebUI for chat or integrate directly into VS Code with AI Toolkit for private, offline code development.
Launch App →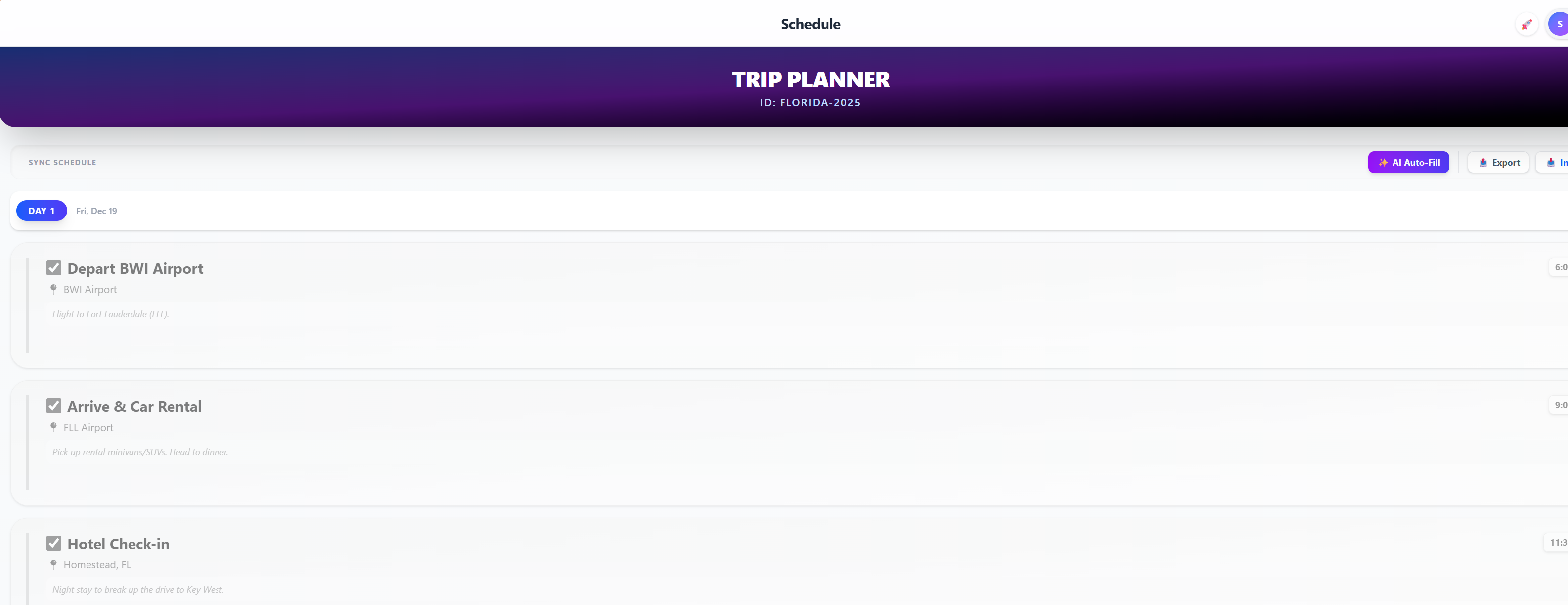
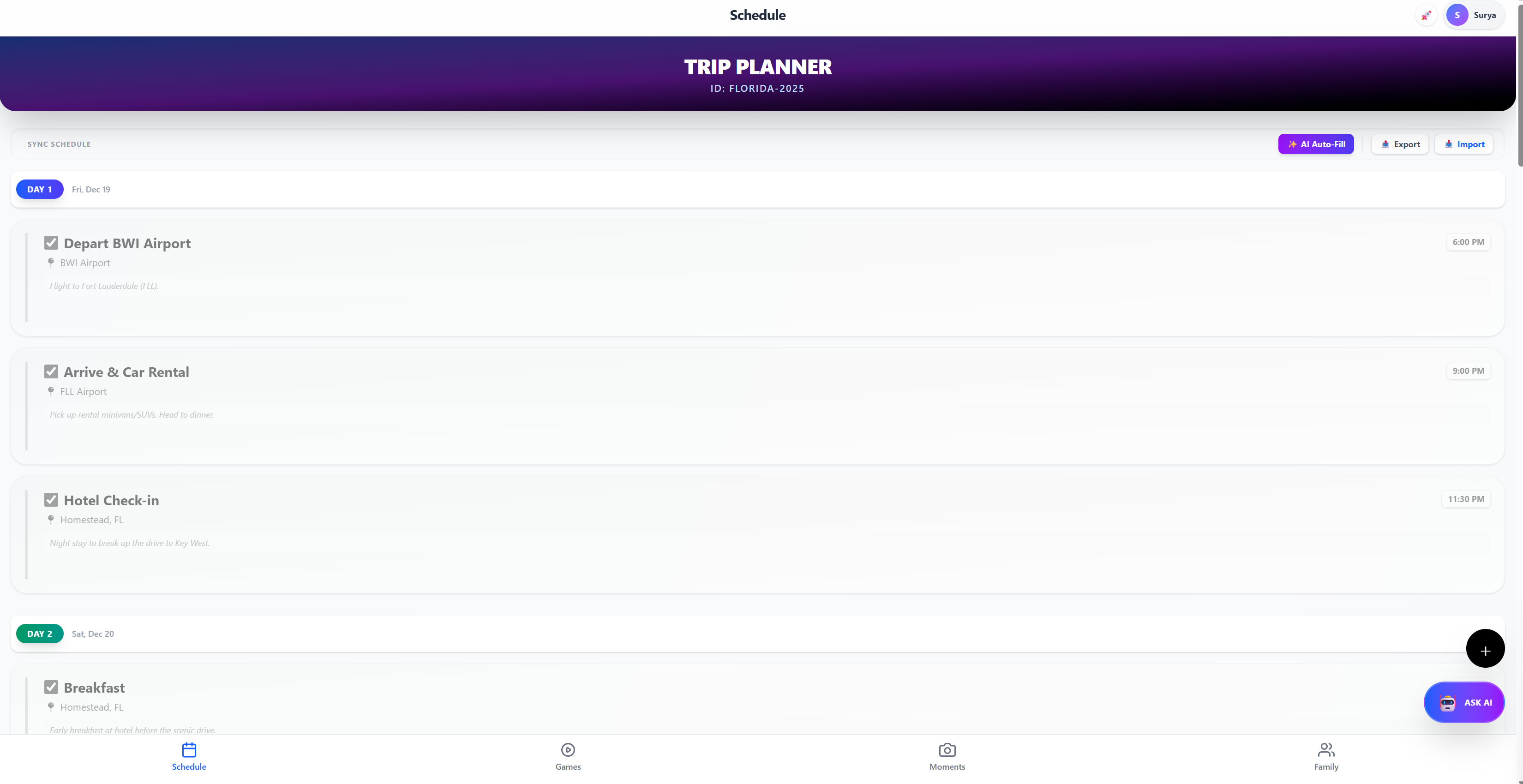
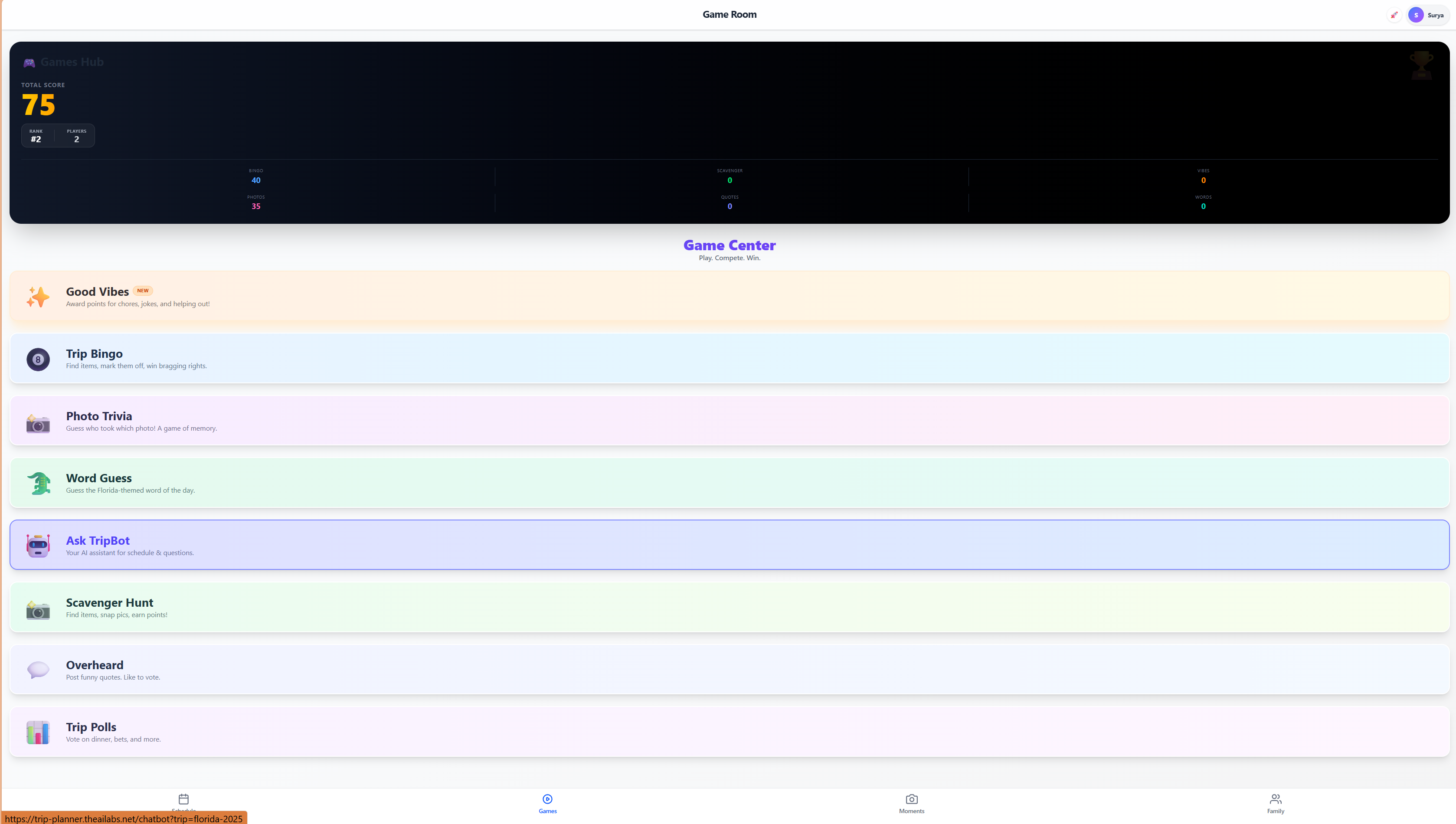
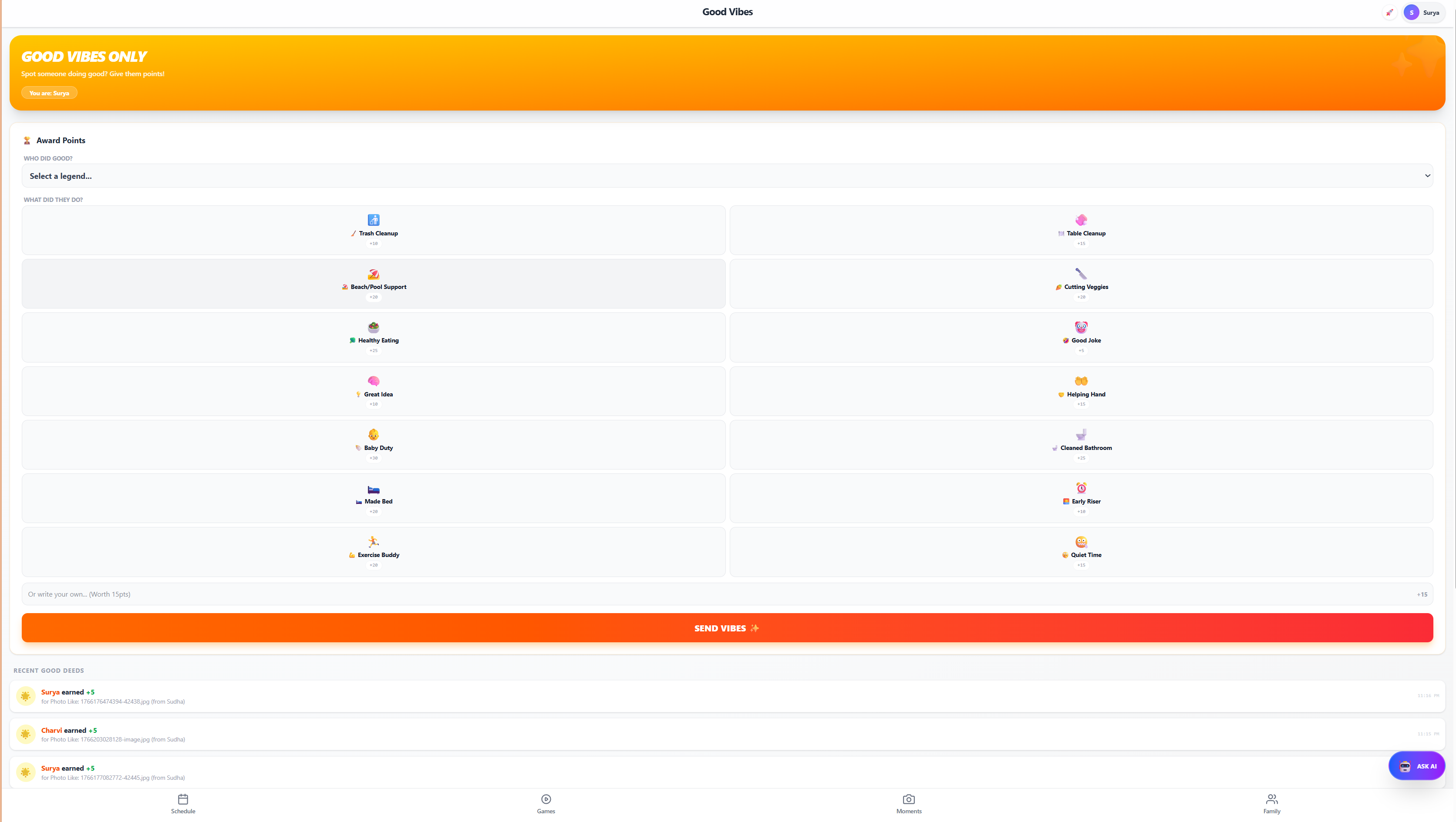
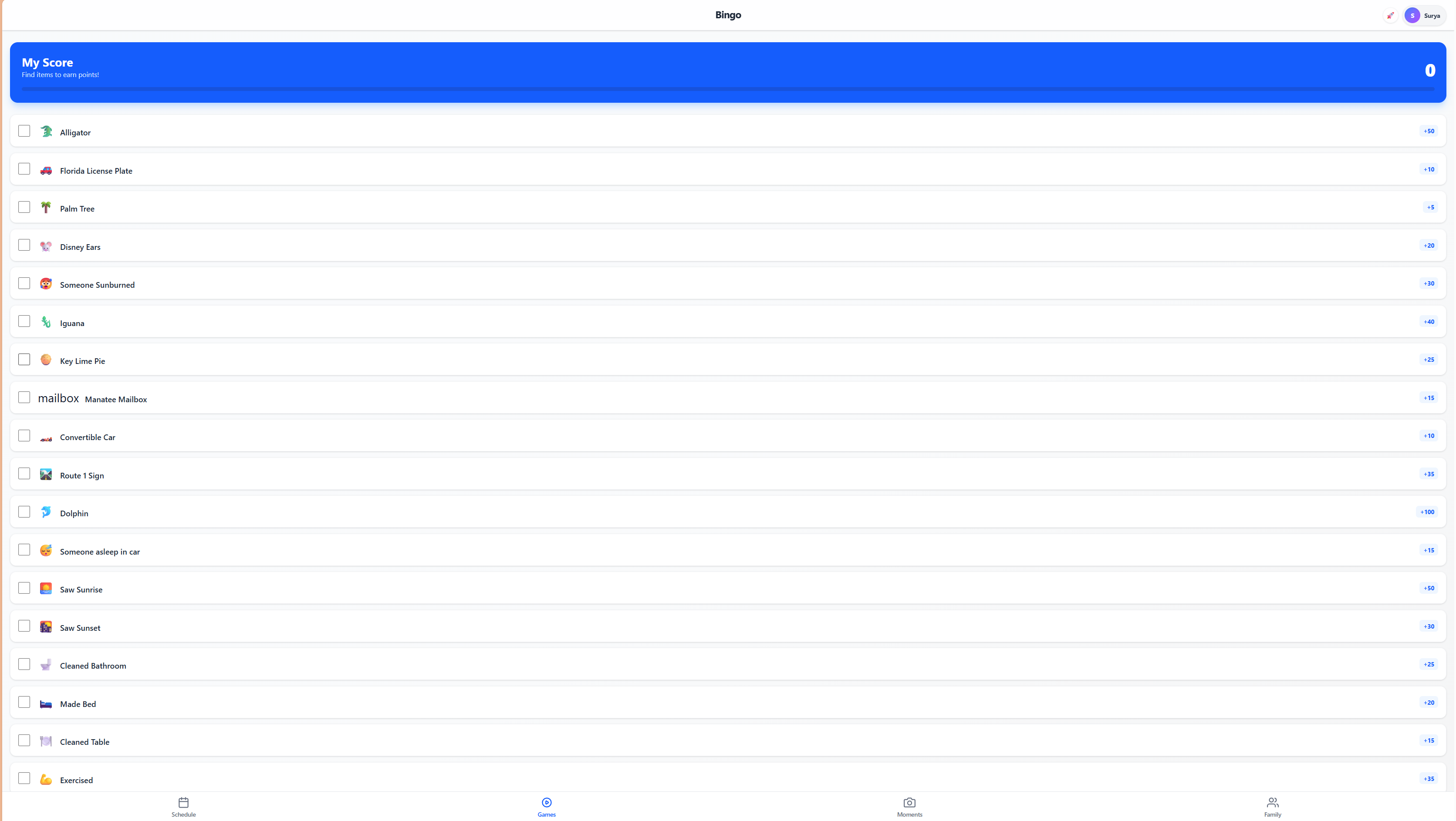
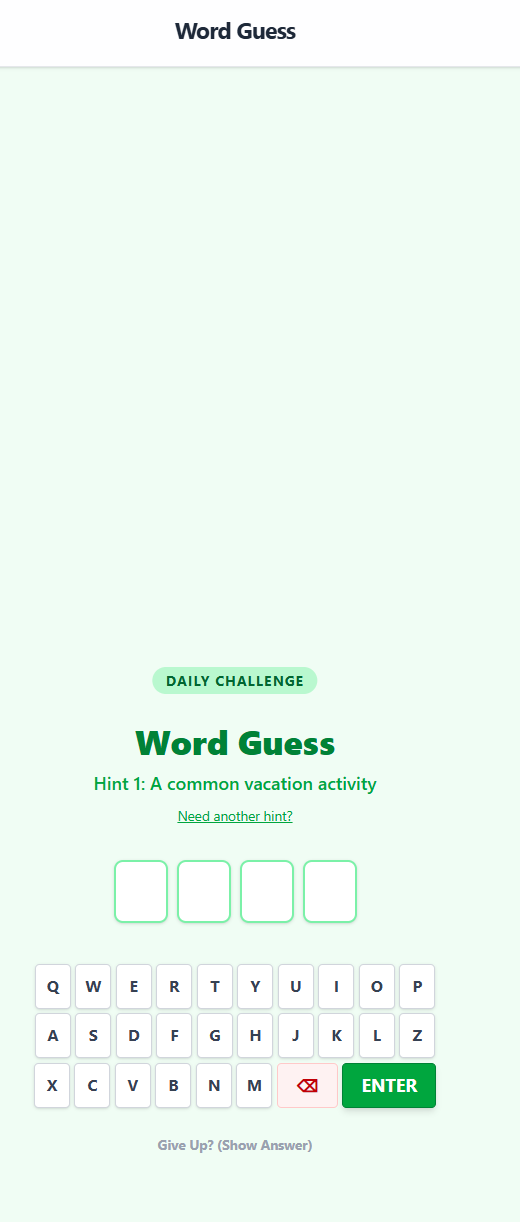
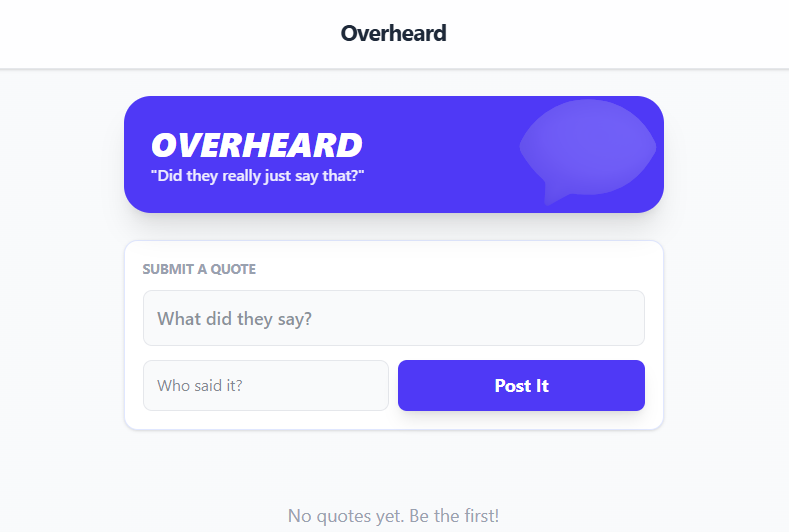
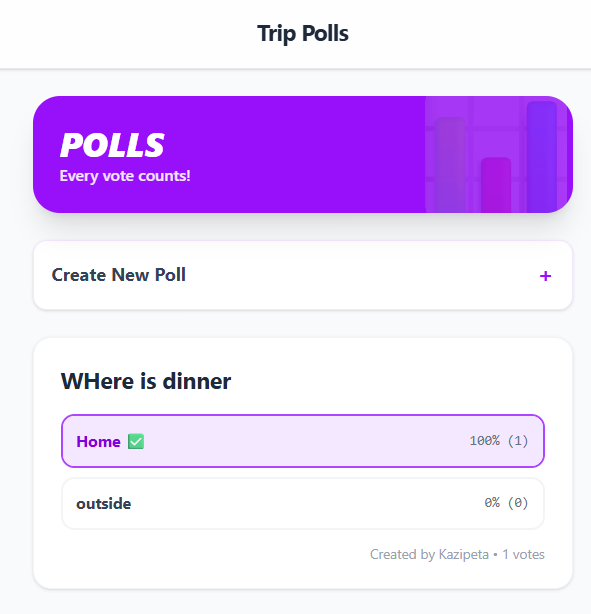
A comprehensive family travel command center. Features a real-time itinerary timeline, interactive scavenger hunt bingo, photo gallery, and traveler directory.
Launch App →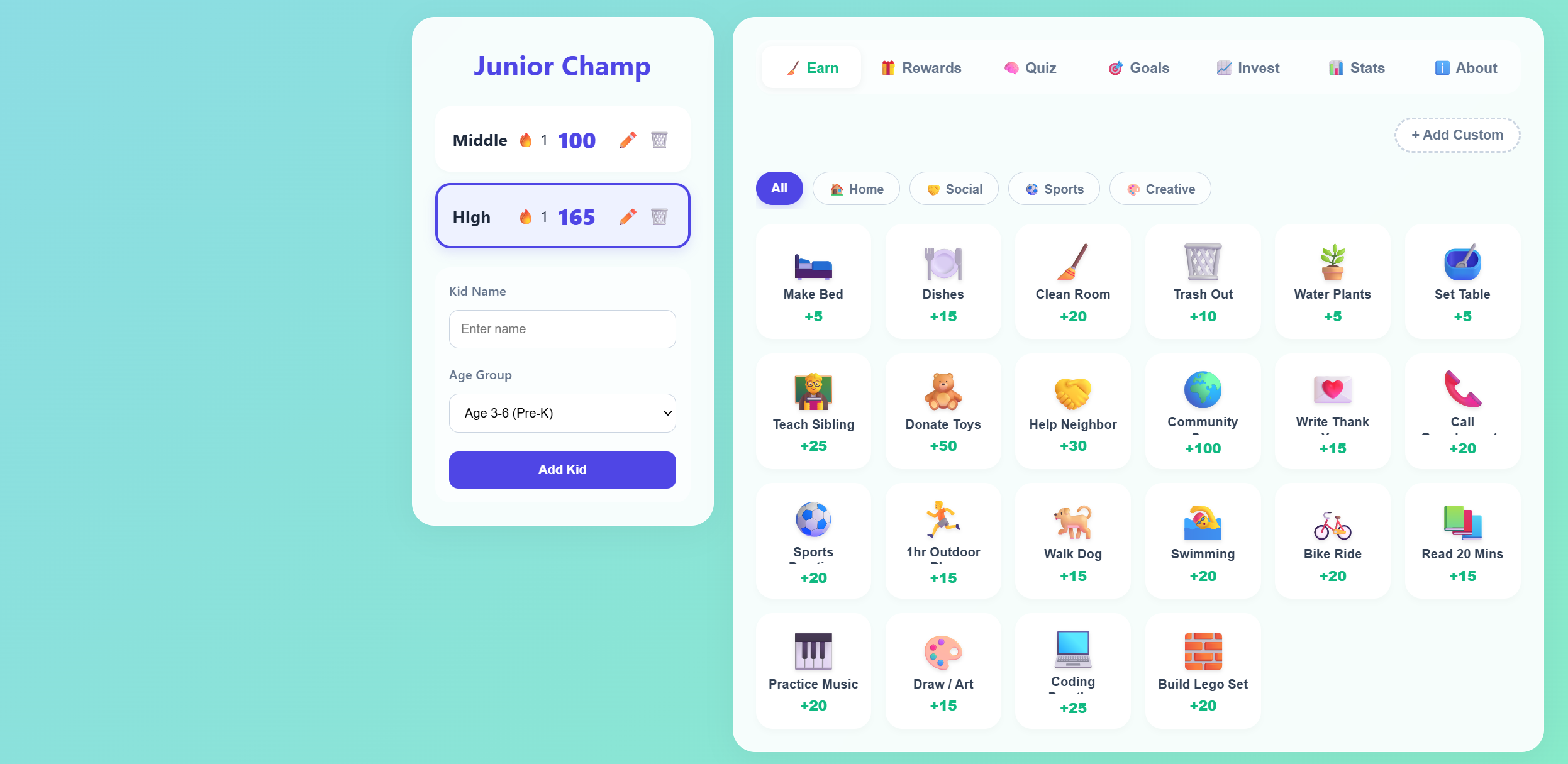
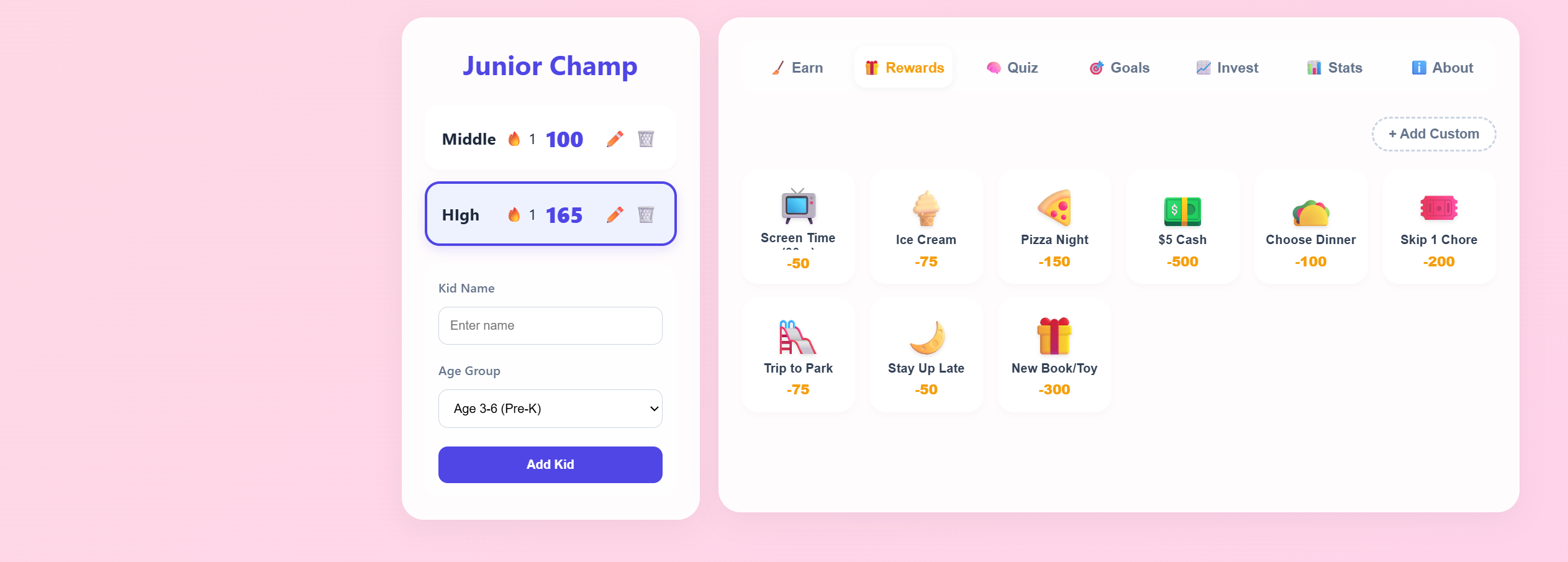
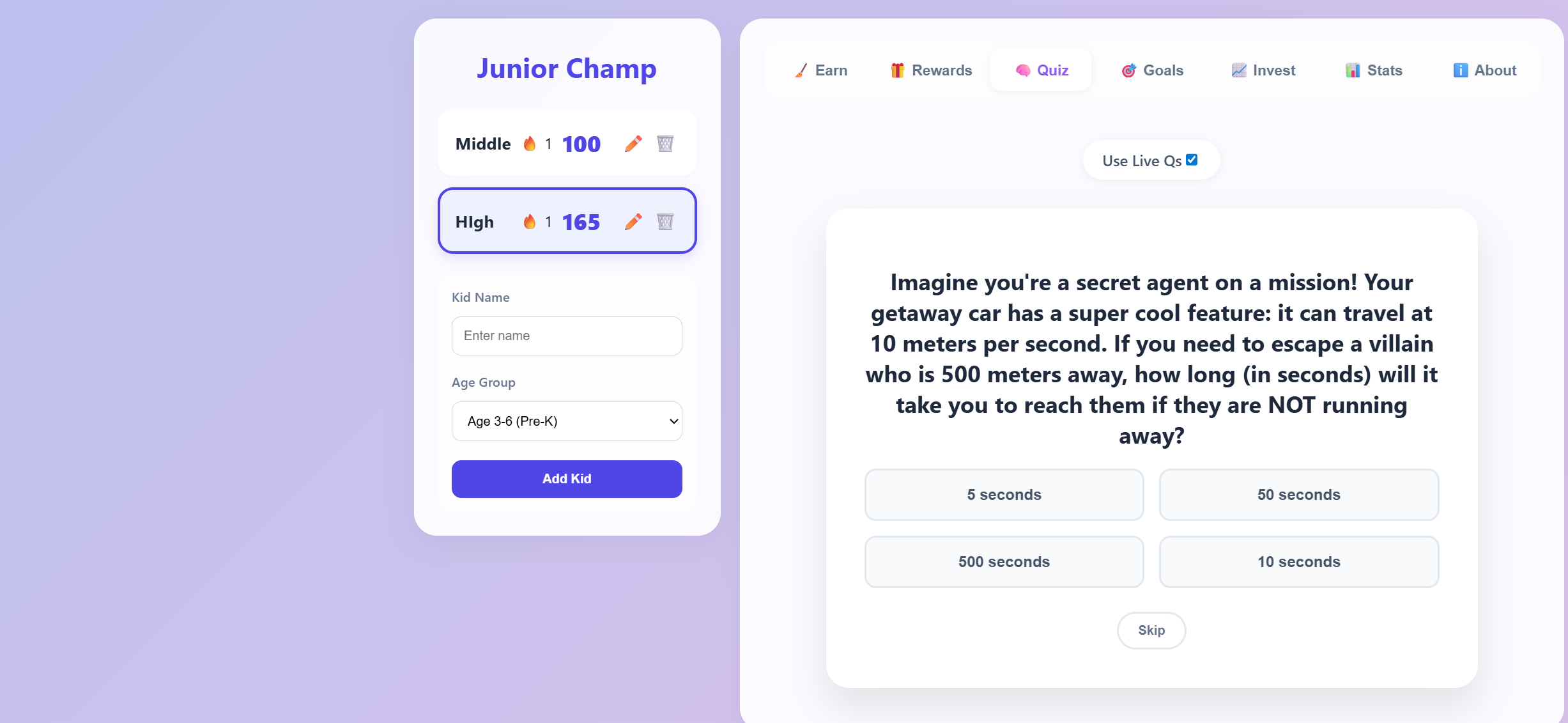
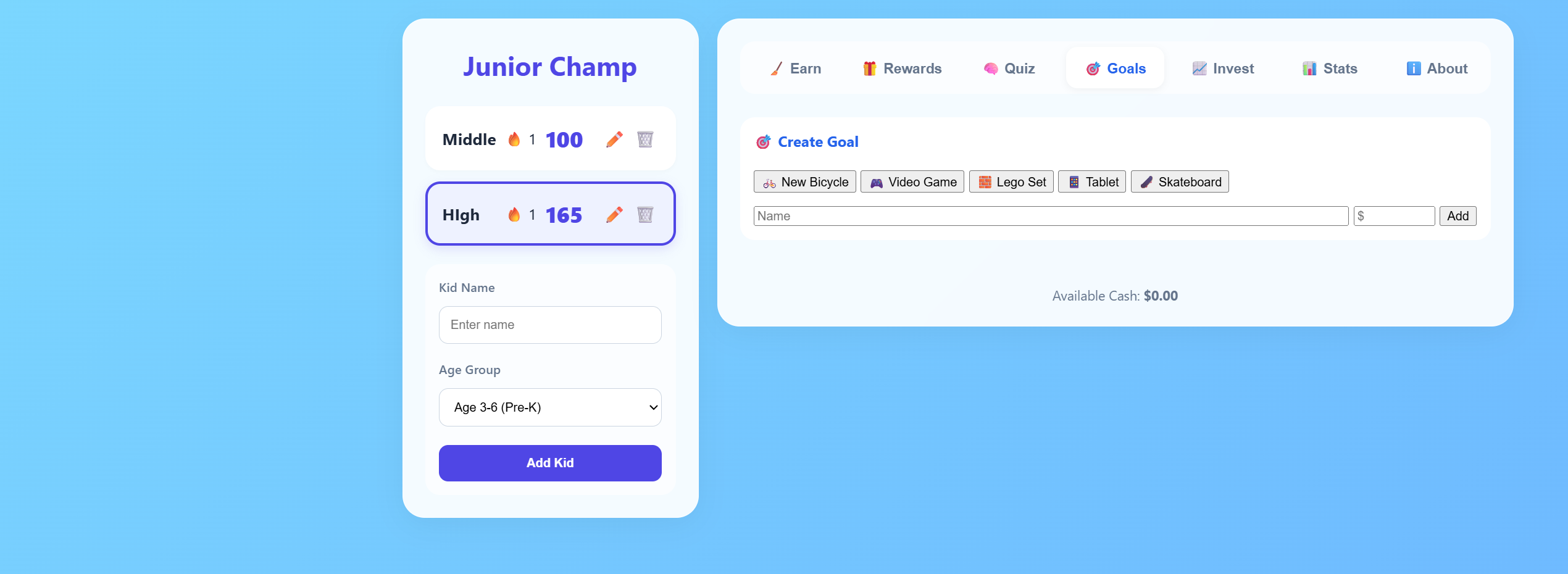
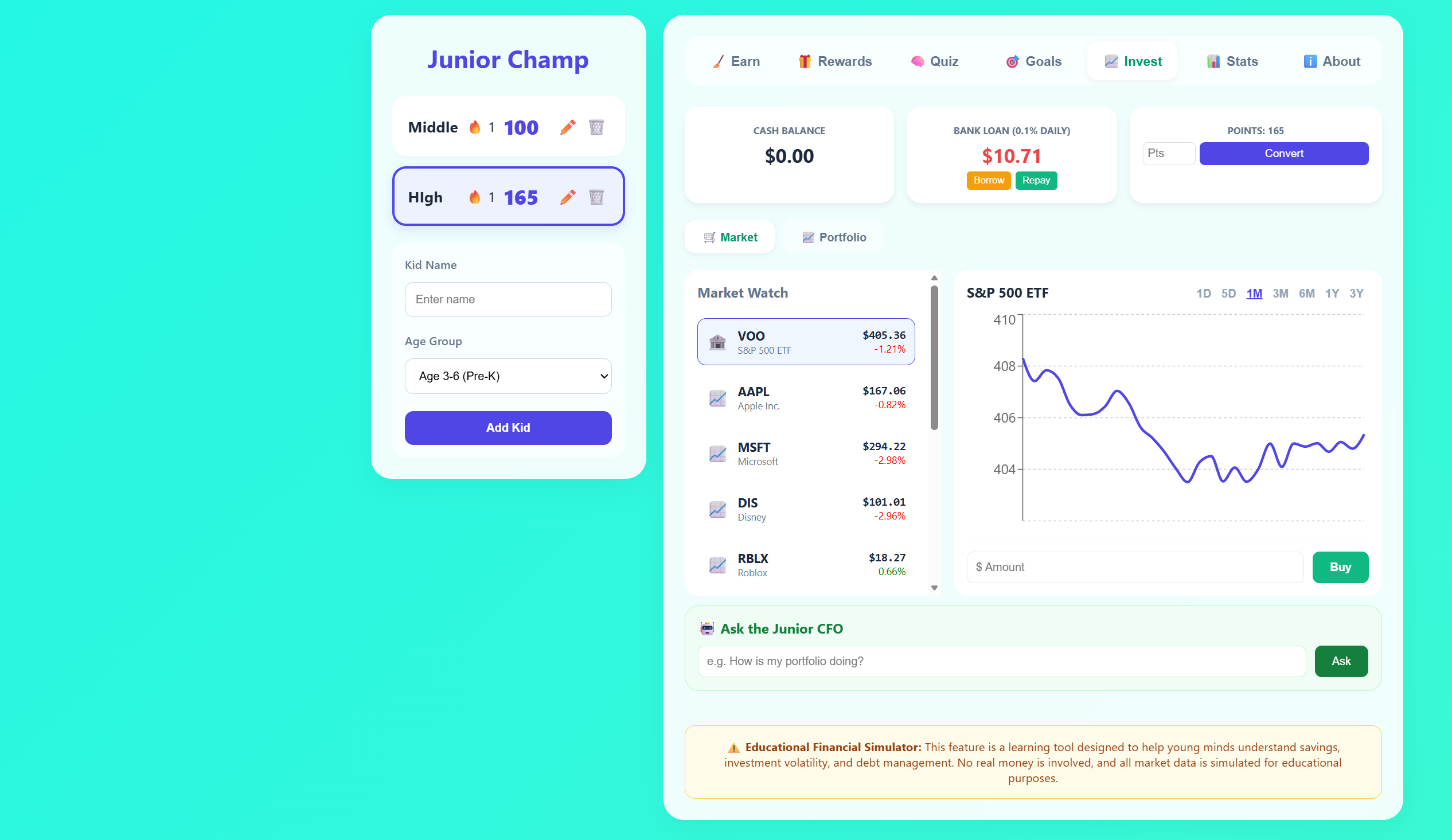
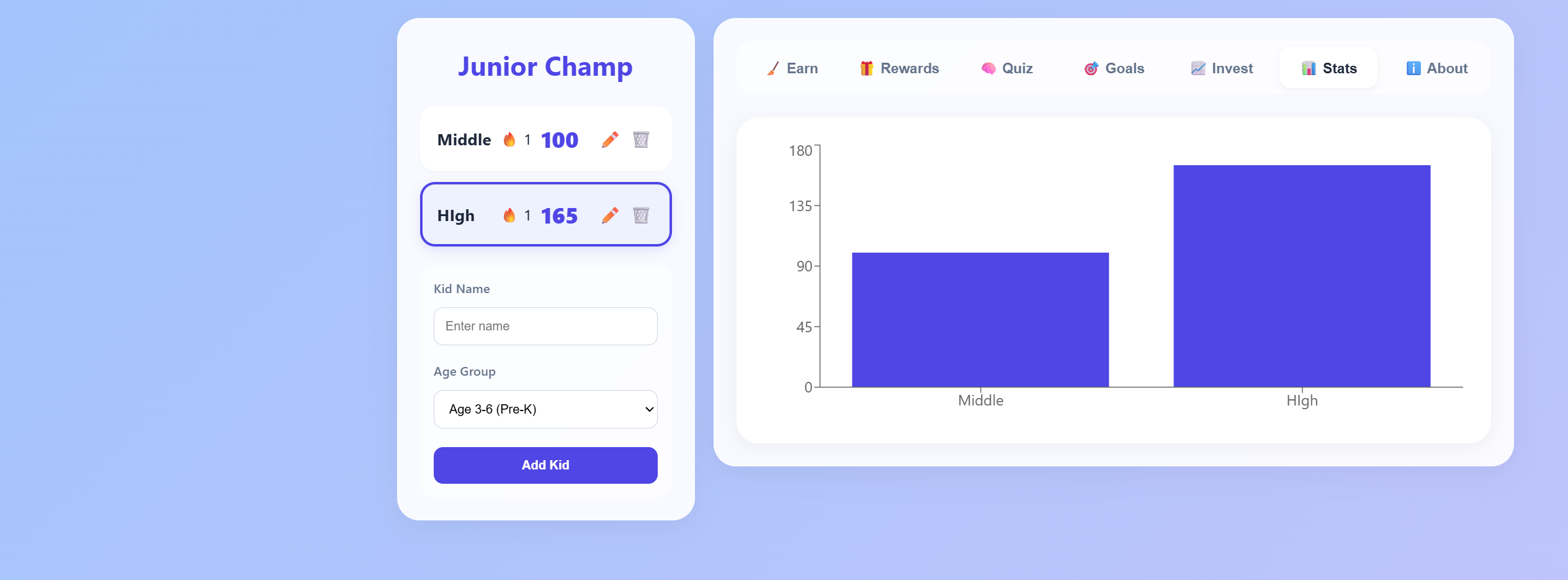
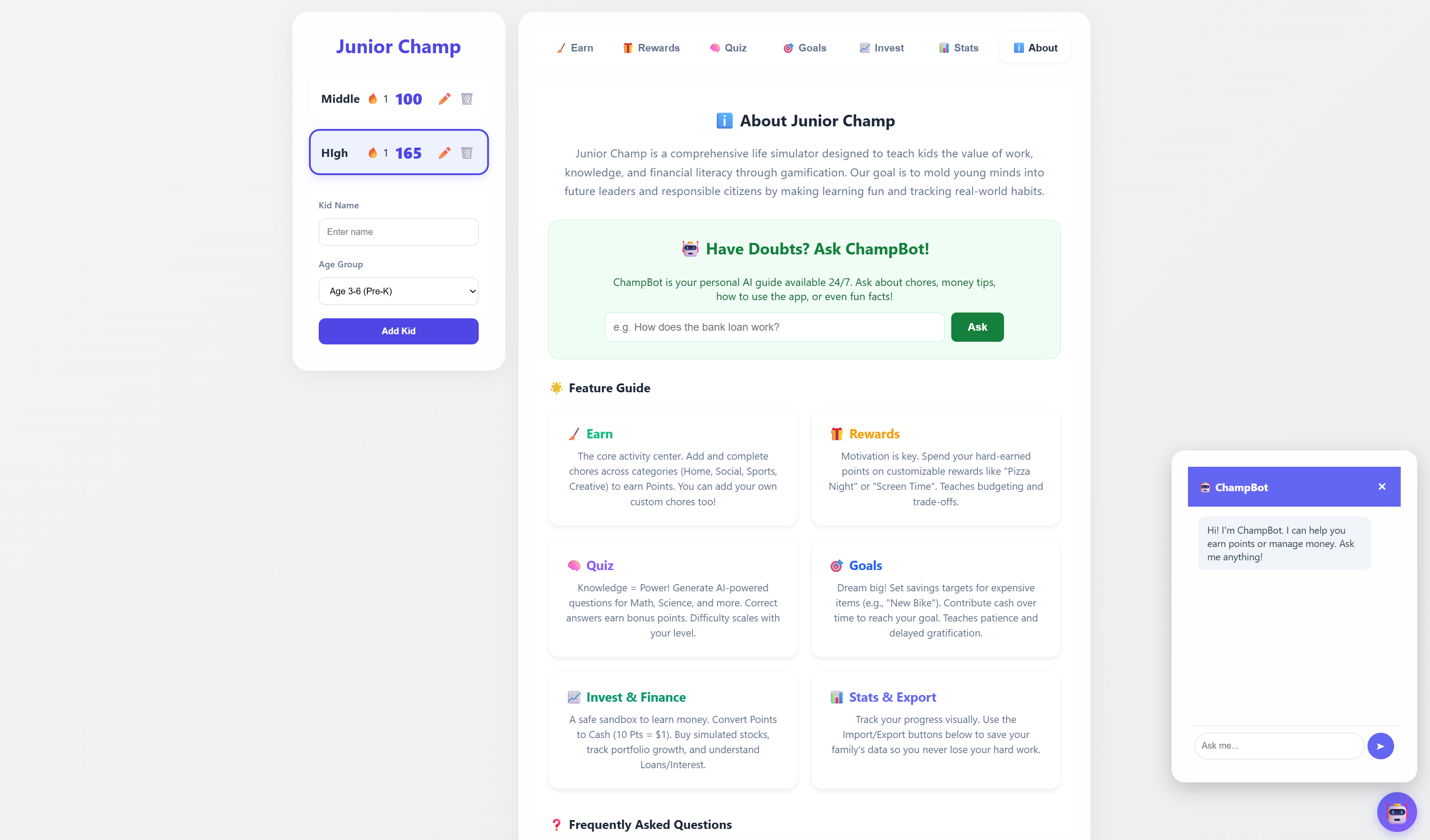
A fun, gamified chore tracker designed for kids. Helps build good habits through a colorful interface with rewards, progress tracking, and interactive checklists.
Launch App →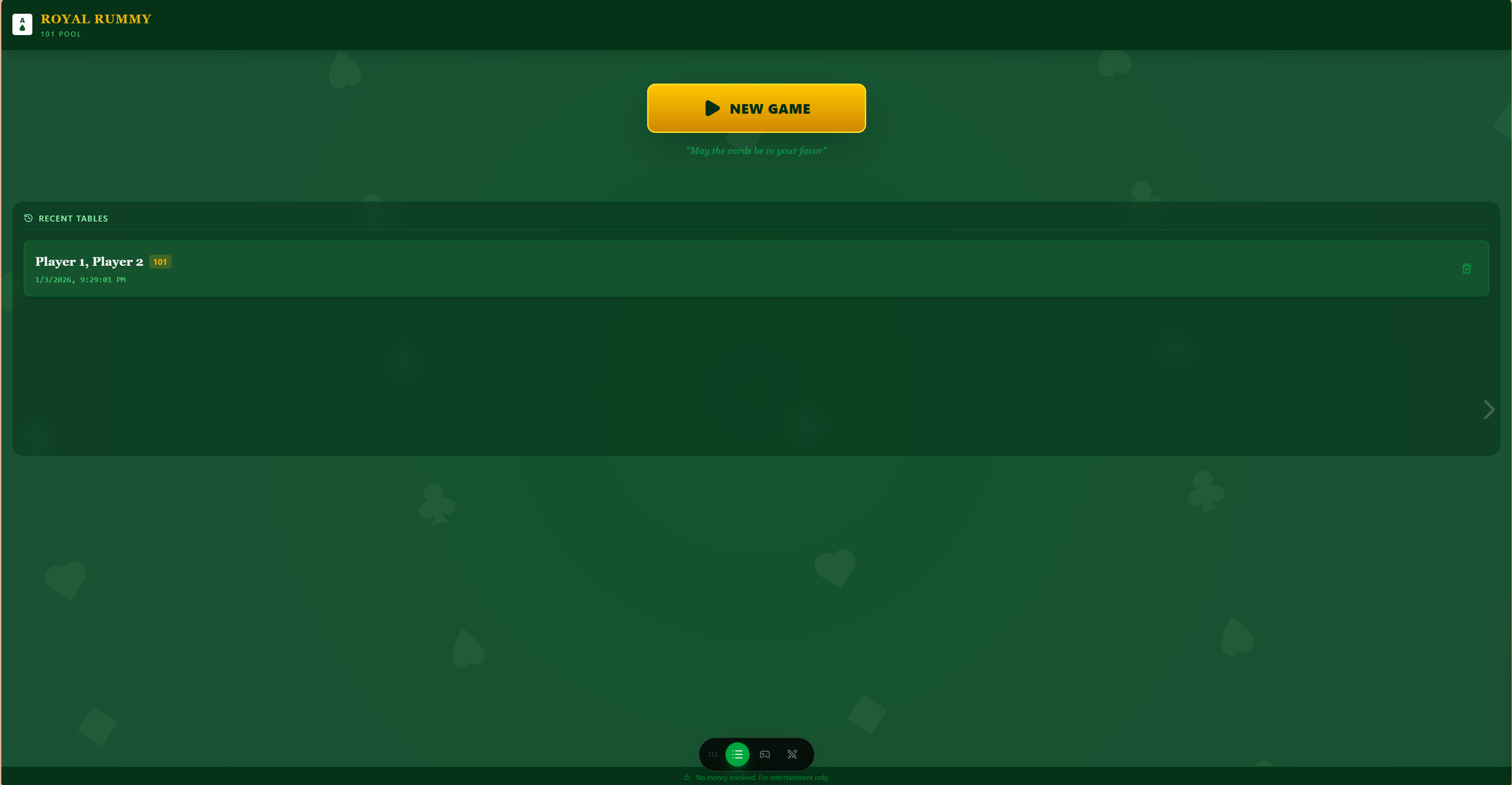
An elegant digital scorekeeper for card games. Features a sleek dark UI, custom player management, and automatic score calculation for a seamless gaming night.
Launch App →Yes. Our setups (Ollama, LocalAI) are designed to run completely offline or behind a secure firewall. Your prompts and documents never leave your local hardware, making it compliant with strict data privacy needs.
For decent performance with Llama 3 (8B), a Mac Mini M2/M3 or an NVIDIA RTX 3060/4060 is sufficient. For larger models (70B) or heavy RAG workloads, we recommend dual RTX 3090/4090 setups or Mac Studio with 64GB+ RAM.
We replace cloud devices with local "satellites" (like ESP32 speakers). These stream audio to your local server (Home Assistant + Whisper), which processes the command and acts on it without sending voice data to Amazon or Google.
Absolutely. Our RAG (Retrieval Augmented Generation) pipeline OCRs your documents and stores them in a local vector database. You can ask "How much did I spend on coffee in 2023?" and it will analyze your actual files to answer.
Once set up, it works like an appliance. We use Docker containers for stability. Updates are as simple as pulling the latest image, but the system will run indefinitely without internet if you choose.
Reach out to hello@theailabs.net or use the form below.
Address: 5710 Stone School Ln, Frederick, MD 21704
Phone: 240-802-9509